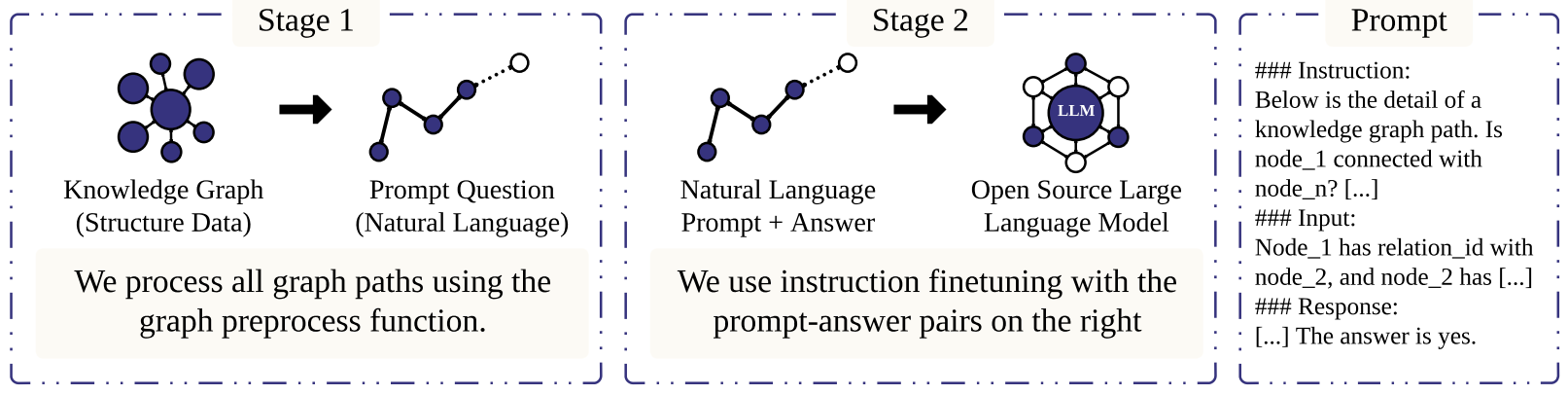
The task of multi-hop link prediction within knowledge graphs (KGs) stands as a challenge in the field of knowledge graph analysis, as it requires the model to reason through and understand all intermediate connections before making a prediction. In this paper, we introduce the Knowledge Graph Large Language Model (KG-LLM), a novel framework that leverages large language models (LLMs) for knowledge graph tasks. We first convert structured knowledge graph data into chain-of-thought (CoT) natural language and then use these CoT prompts to fine-tune LLMs to enhance multi-hop link prediction in KGs.
By converting knowledge graphs into CoT prompts, our framework allows LLMs to better understand and learn the latent representations of entities and their relationships within the knowledge graph. Our analysis of real-world datasets confirms that our framework improves generative multi-hop link prediction in KGs, underscoring the benefits of incorporating CoT and instruction fine-tuning during training. Our findings also indicate that our framework substantially improves the generalizability of LLMs in responding to unseen prompts.
In this paper, we conduct experiments to evaluate the effectiveness of the proposed KG-LLM frameworks to answer the following several key research questions:
1. Q1: Which framework demonstrates superior efficacy in multi-hop link prediction tasks in the absence of ICL?
2. Q2: Does incorporating ICL enhance model performance on multi-hop link prediction task?
3. Q3: Is the KG-LLM framework capable of equipping models with the ability to navigate unseen prompts during multi-hop relation prediction inferences?
4. Q4: Can the application of ICL bolster the models' generalization ability in multi-hop relation prediction tasks?
Keywords: Large Language Models, Knowledge Graph, Link Prediction

An Example of Prompt Used in the Multi-hop Link Prediction Training Process: Models processed through the ablation framework will be trained using the ablation knowledge prompt (left), whereas models processed via the KG-LLM frameworkwill be trained on the KG-LLM knowledge prompt (right).
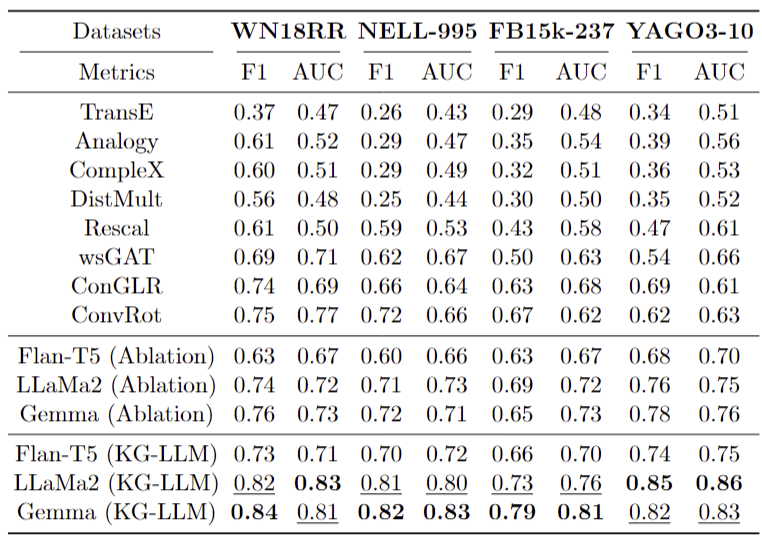
- The KG-LLM framework outperformed traditional approaches and ablation models across all datasets.
- The traditional GNN model, especially ConvRot, showed relatively good performance, surpassing ablation models on the WN18RR dataset.
- The results highlight the effectiveness of the KG-LLM framework, enriched with Chain-of-Thought (CoT) reasoning and IFT.
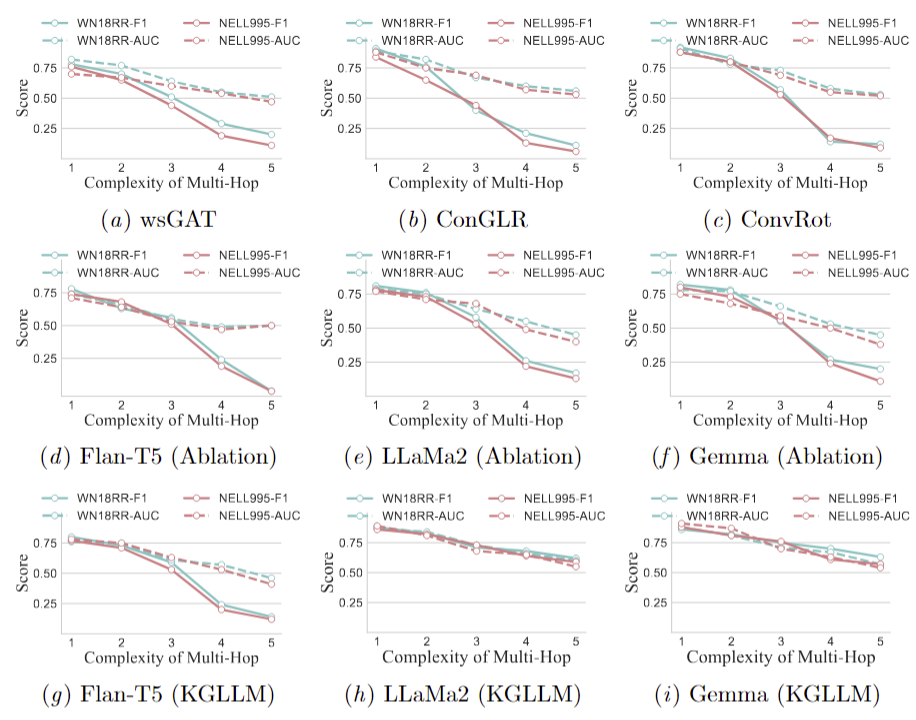
- We evaluated the performance of GNN, ablation, and KG-LLM framework models across different levels of hop complexity on the WN18RR and NELL-995 datasets.
- GNN and ablation models' performance significantly declines as hop complexity increases.
- As hop complexity grows, these models tend to frequently respond with 'No' to most questions, leading to: F1 scores close to 0 and AUC scores around 0.5.
- In contrast, the KG-LLM framework models effectively manage the challenge, maintaining consistent performance even at five-hops, with the exception of the Flan-T5 model.
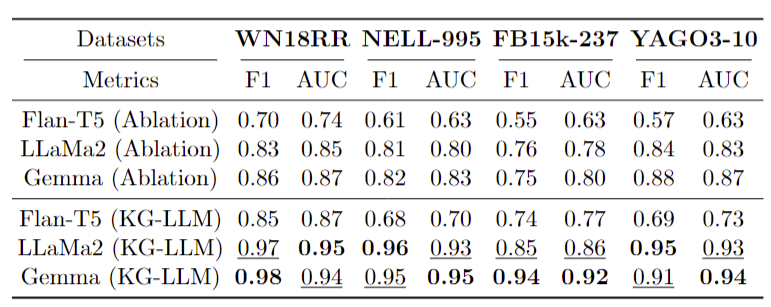
We reveals a notable enhancement in the performance of models under the ablation framework, with LLaMa2 and Gemma models achieving an F1 and AUC score exceeding 80% in WN18RR and NELL-995 datasets. Remarkably, the adoption of ICL within the KG- LLM framework resulted in a significant performance uplift. Notably, the Gemma model achieved a staggering 98% F1 score on the first dataset, while LlaMa2 recorded a 96% F1 score on the second dataset.
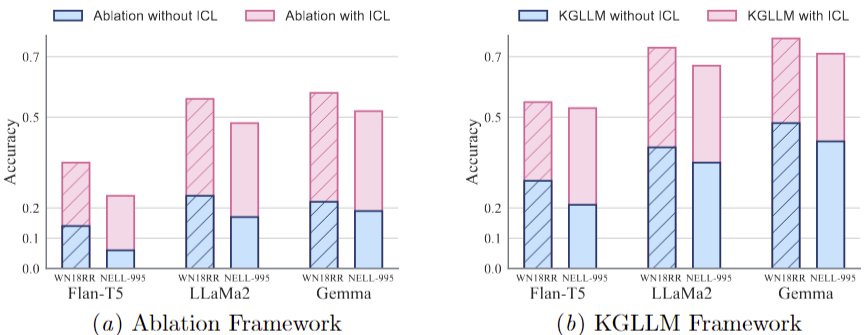
For experiments on multi-hop relation prediction without in-context learning (ICL):
- Both frameworks had limited performance without ICL, though the KG-LLM framework performed marginally better.
- Models tended to provide 'yes' or 'no' answers for most questions, similar to previous multi-hop link prediction tasks.
- Some questions elicited random responses from the models.
For experiments on multi-hop relation prediction with in-context learning (ICL):
- There is significant improvement in models' generalization abilities under both ablation and KG-LLM frameworks, compared to performance without ICL (blue bars).
- KG-LLM framework models, particularly LlaMa2 and Gemma, achieved over 70% accuracy on WN18RR datasets when using ICL.
@article{shu2024knowledge,
title={Knowledge Graph Large Language Model (KG-LLM) for Link Prediction},
author={Shu, Dong and Chen, Tianle and Jin, Mingyu and Zhang, Yiting and Du, Mengnan and Zhang, Yongfeng},
journal={arXiv preprint arXiv:2403.07311},
year={2024}
}