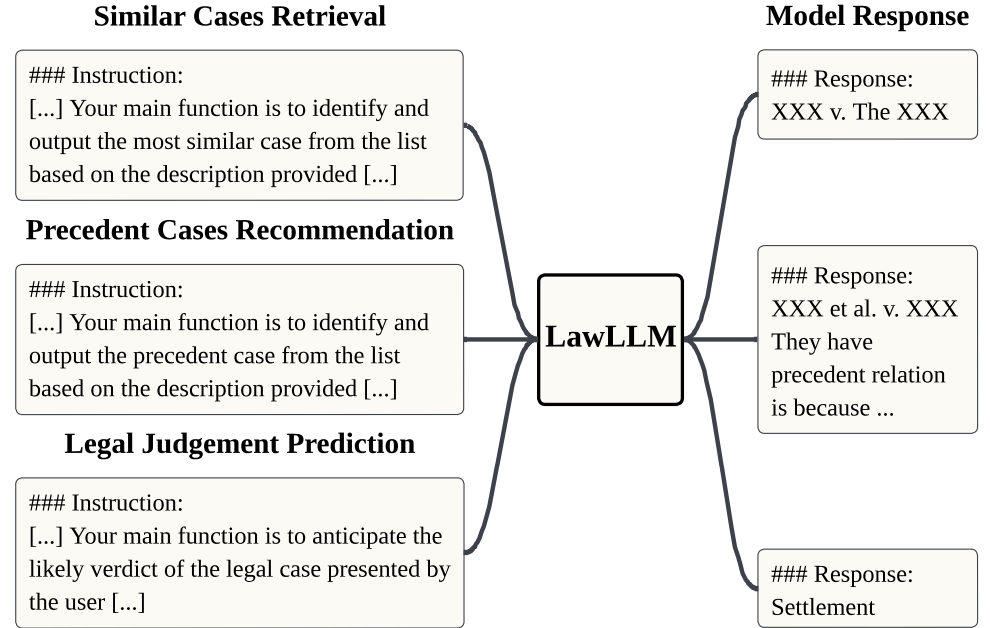
In the rapidly evolving field of legal analytics, finding relevant cases and accurately predicting judicial outcomes are challenging because of the complexity of legal language, which often includes specialized terminology, complex syntax, and historical context. Moreover, the subtle distinctions between similar and precedent cases require a deep understanding of legal knowledge. Researchers often conflate these concepts, making it difficult to develop specialized techniques to effectively address these nuanced tasks. In this paper, we introduce the Law Large Language Model (LawLLM), a multi-task model specifically designed for the US legal domain to address these challenges. LawLLM excels at Similar Case Retrieval (SCR), Precedent Case Recommendation (PCR), and Legal Judgment Prediction (LJP).
In our paper, we distinguishes between precedent cases and similar cases, providing clarity on the objectives of each task. This clarification enables the future research to develop tailored strategies for those tasks. The experimental results indicate that LawLLM outperformed all baseline models, including the GPT-4 model, across all three tasks. These results highlight LawLLM's robust capabilities in the legal domain.
Keywords: Large Language Models, Multitask Learning, Legal System, Natural Language Processing
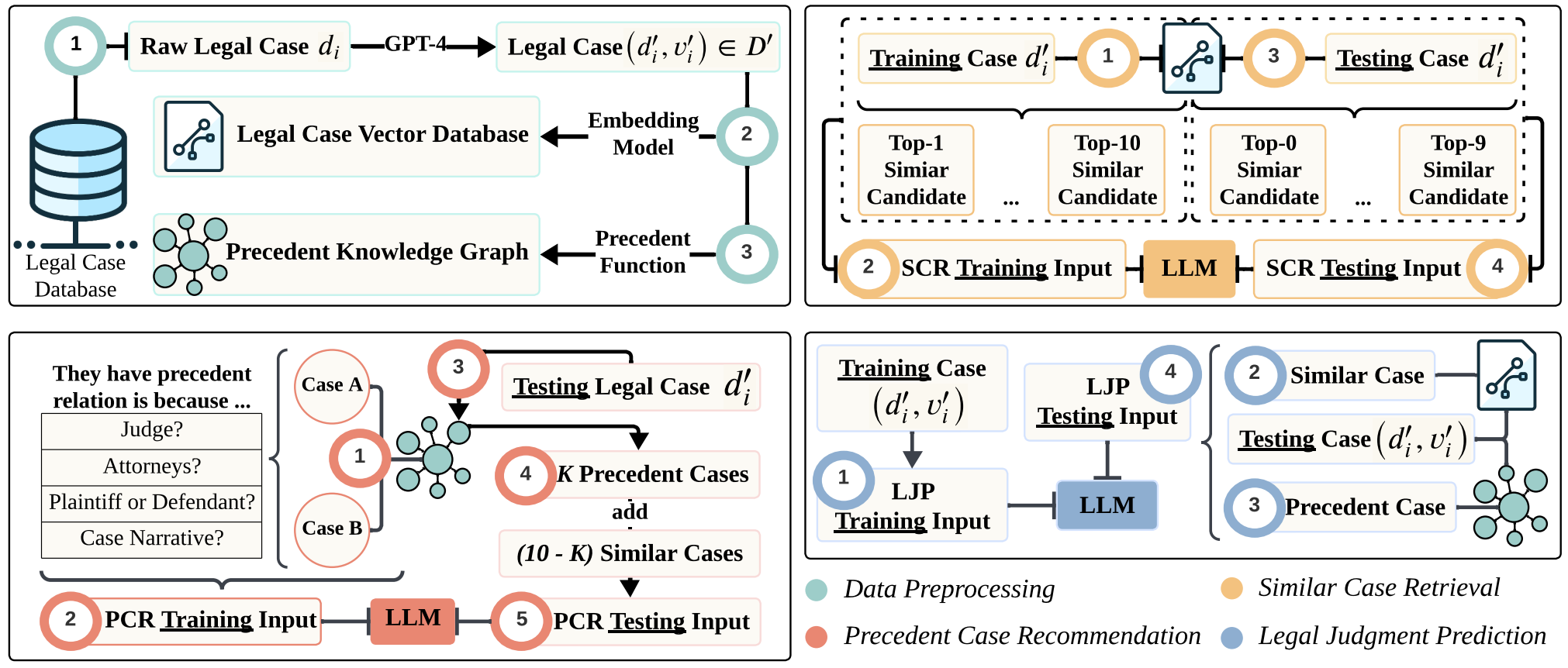
Our methodological framework is divided into four distinct parts: Data Preprocessing, SCR Processing, PCR Processing, and LJP Processing.
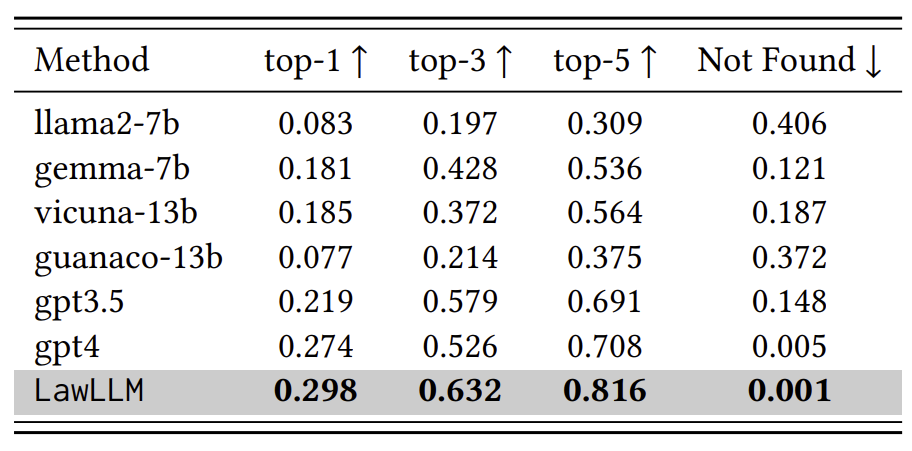
LawLLM outperformed the baseline models in all categories. Specifically, it achieved the highest accuracy in top-1, top-3, and top-5 retrieval rates, with scores of 29.8%, 63.2%, and 81.6% respectively. Remarkably, it also demonstrated minimal hallucination, as indicated by the not-found rate of 0.1%
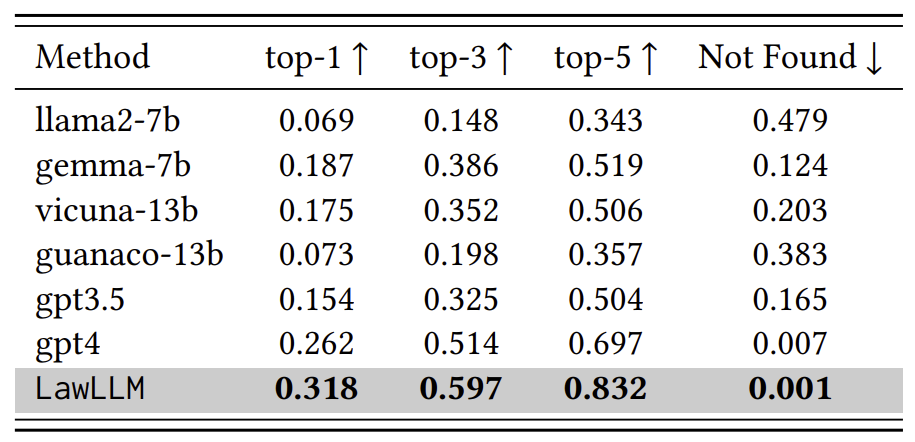
LawLLM model again outperformed other baseline methods. It achieved the best results with a top-1 rate of 31.8%, top-3 rate of 59.7%, and top-5 rate of 83.2%. Additionally, the LawLLM model exhibited an low not-found rate of 0.1%.
One notable insight from comparing SCR and PCR results is that most baseline models exhibited a performance drop in the PCR task compared to SCR. For instance, the GPT-4 model achieved scores of 27.4%, 52.6%, 70.8%, 0.5% in SCR top-k and “Not Found” metrics, while in the PCR task, its scores dropped to 26.2%, 51.4%, 69.7% and 0.7%. This decline underscores the greater difficulty of identifying precedent cases compared to similar cases, as models cannot rely solely on textual similarity when determining precedent relationships. Instead, they must consider nuanced factors such as legal relevance. This performance difference reinforces the our previous assertion that precedent cases are distinct from similar cases, emphasizing the importance of distinguishing between the two concepts in the legal domain.
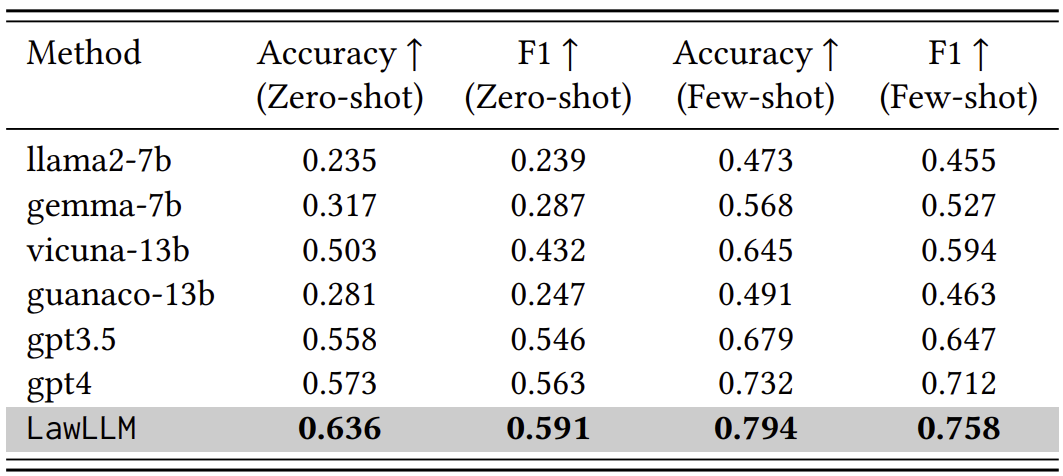
LawLLM surpasses all baseline methods in both zero-shot and few-shot scenarios for the LJP task. In the zeroshot scenario, LawLLM achieves an accuracy of 0.636 and an F1 score of 0.591, significantly outperforming the second best model, GPT-4, which scores 0.573 and 0.563 in accuracy and F1, respectively. In the few-shot scenario, LawLLM maintains its superior performance, reaching an accuracy of 0.794 and an F1 score of 0.758.
Additionally, all models demonstrate higher performance in the few-shot in-context learning (ICL) scenario compared to the zeroshot setting. For instance, LLaMA2-7b shows an increase from 0.235 to 0.473 in accuracy, and from 0.239 to 0.455 in F1 score. This pattern indicates that all models benefit from incorporating a few ICL examples, which helps them better understand the task.
@article{shu2024lawllm,
title={LawLLM: Law Large Language Model for the US Legal System},
author={Shu, Dong and Zhao, Haoran and Liu, Xukun and Demeter, David and Du, Mengnan and Zhang, Yongfeng},
journal={arXiv preprint arXiv:2407.21065},
year={2024}
}